About Problem Management
Problem Management is the process responsible for managing the lifecycle of all problems. The primary objectives of Problem Management are to:
Process Definition
Problem Management includes the activities required to diagnose the root cause of incidents and to determine the resolution to those problems. It is also responsible for ensuring that the resolution is implemented through the appropriate control procedures.
Objectives
Problem Management Flow Chart
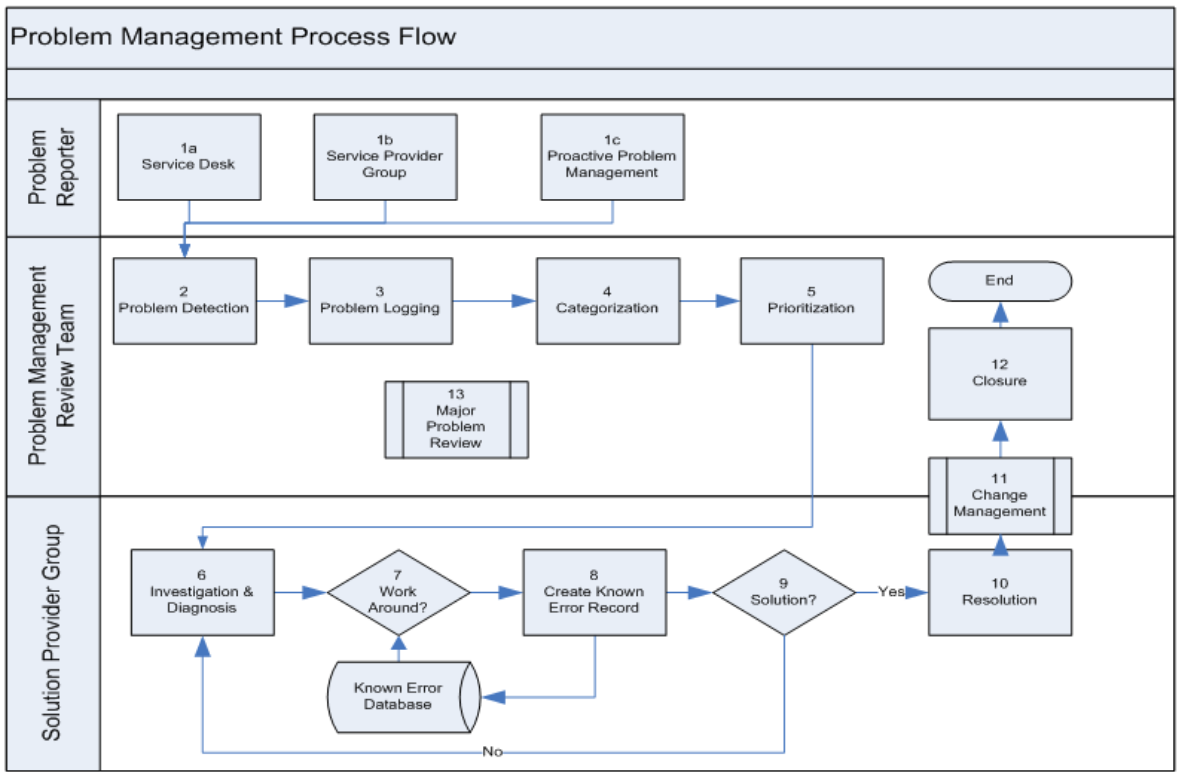
Definitions
Reporter. A person who is requesting for a problem case to be opened.
Method of Notification. The mode of medium used by the reporter to report a problem. The following are modes by which the Reporter can report a problem (however, this can customized):
Callback Method. The preferred method to callback the reporter. The following are the modes of callback:
Category. Denotes to which group of IT domain the issue is related to. The following are the categories:
User Administration
Impact Level. The measure of the effect of a Problem on the Business Process. Impact is used to assign the priority.
There are three grades of impact:
Urgency. A measure of how long it will be until an Incident, Problem or Change has a significant Impact on the Business. For example a high impact problem may have low urgency, if the impact will not affect the business until the end of the financial year. Impact and Urgency are used to assign Priority.
There are three grades of urgency such as:
Priority. A Category used to identify the relative importance of a Problem. Priority is based on Impact and Urgency, each level of priority has a specified SLA within which the problem needs to be resolved.
There are five grades of priority:
State. Shows the current stage in the Lifecycle of the associated problem.
There are the following statuses:
Type. A category that determines the nature of a problem. There are the following types:
Assignee. The role to whom the problem is assigned for resolution.
Description Gives a brief or the detailed description of the problem.
Known Error. An Entry that includes the symptoms related to open problems and the incidents the problem is known to create. If available, the entry will also have a link to entries in the Knowledge Base which show potential work arounds to the problem.
Known Error Record. As soon as the diagnosis is far enough along to clearly identify the problem and its symptoms, and particularly where a workaround has been found (even though it may not yet be a permanent resolution), a Known Error must be raised so that if further incidents or problems arise, they can be identified and the service is restored more quickly. However, in some cases it may be advantageous to raise a Known Error even earlier in the overall process – just for information purposes, for example – even though the diagnosis may not be complete or a workaround found. The known error record must contain all known symptoms so that when a new incident occurs, a search of known errors can be performed and find the appropriate match.
Diagnosis Notes. Steps taken to diagnose the problem are documented.
Work Around. In some cases, the workaround may be instructions provided to the customer on how to complete their work using an alternate method. These workarounds need to be communicated to the Service Desk so they can be added to the Knowledge Base and therefore be accessible by the Service Desk to facilitate resolution during future recurrences of the incident. In cases where a workaround is found, it is important that the problem record remains open and details of the workaround are always documented within the Problem Record.
Test Plan. Steps taken to monitor and test the resolution are documented.
Resolution Notes. Resolution information is documented.
Closure code. The act of changing the status of a problem. There are the following closure codes.
Closure Note. Closure information is documented by the assignee.
Custom Timescale. Defines define the Response time and the Resolution time for a specific problem model /Problem. If custom timescale is not set, the system uses default timescales as defined in Problem Timescales.
Problem Policy
The Problem process should be followed to find and correct the root cause of significant or recurring incidents. Problems should be prioritized based upon impact to the customer and the availability of a workaround.
Problem Ownership remains with Quality Assurance. Regardless of where a problem is referred to during its life, ownership of the problem remains with the Quality Assurance at all times. Quality Assurance remains responsible for tracking progress, keeping users informed, and ultimately for Problem Closure.
Rules for re-opening problems. Despite all adequate care, there will be occasions when problems reoccur even though they have been formally closed. If the related incidents continue to occur under the same conditions, the problem case should be re-opened. If similar incidents occur but the conditions are not the same, a new problem should be opened. Workarounds should be in conformance with the clients standards and policies.
Related Topics